

Bölüm 01
Giriş
Dijital platformların kullanıcı tabanı genişledikçe, bu platformların ürettiği davranışsal veri de katlanarak büyümektedir. 2024 yılı itibarıyla yalnızca ABD'de yetişkin nüfusun yüzde otuz dördü ChatGPT'yi düzenli olarak kullandığını bildirirken (Wang vd., 2025), Meta ve Google gibi platformlar kullanıcı profillerini çok boyutlu davranışsal çıkarımlarla sürekli güncellemektedir (Pan vd., 2025). Bu süreç, bireylerin davranışsal verilerinin ham maddeye dönüştürüldüğü, işlendiği ve tahmin modellerine beslendiği sistematik bir yapı oluşturmaktadır. Söz konusu yapı, algoritmik profilleme pipeline'ı olarak tanımlanmakta ve veri toplamadan kişiselleştirilmiş davranışsal manipülasyona uzanan uçtan uca bir süreci kapsamaktadır.
Algoritmik profilleme, teknik bir kavram olmanın ötesine geçerek demokratik süreçler, ekonomik karar alma ve bireysel özerklik üzerinde ölçülebilir etkiler doğurmaktadır. Zuboff (2019), bu yapıyı "gözetim kapitalizmi" olarak tanımlamış; insan deneyiminin başkalarının davranış tahminleri üretmek amacıyla sistematik biçimde çıkarıldığı yeni bir ekonomik düzeni tarif etmiştir. Yeung (2017) ise "hypernudge" kavramıyla, bireylerin farkında olmadan algoritmik yönlendirme ortamlarına hapsedildiğini göstermiştir.
Mevcut literatür, algoritmik profillemenin çeşitli bileşenlerini ayrı ayrı ele almaktadır. Bununla birlikte, veri toplamadan davranışsal manipülasyona uzanan uçtan uca pipeline'ın bütüncül bir teknik incelemesi literatürde yeterince yer bulmamıştır.
BÖLÜM 02
Kavramsal Çerçeve
2.1 Algoritmik Profilleme Nedir
Algoritmik profilleme, bireylerin dijital ortamlarda bıraktıkları davranışsal izlerin sistematik olarak toplanması, işlenmesi ve bu izlerden psikolojik, demografik ve davranışsal özellikler çıkarılması sürecidir. Bu süreç, bireyi önce matematiksel bir temsile dönüştürmekte; ardından bu temsili tahmin ve yönlendirme amacıyla kullanmaktadır. Grisold vd. (2024), dijital gözetim ortamlarında izleyenlerin izlenenler hakkında katlanarak büyüyen bir bilgi birikimine sahip olduğunu göstermiştir.
2.2 Uçtan Uca Pipeline Kavramı
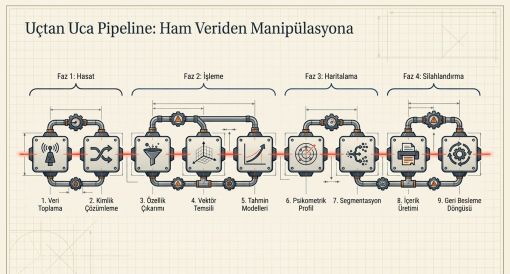
Uçtan uca pipeline kavramı, veri toplamadan nihai çıktı üretimine uzanan tüm aşamaların birbirine entegre ve sürekli geri besleme döngüleriyle bağlı olduğu bir mimariyi tanımlamaktadır.
2.3 Steward (Kahya) Modeli: Özgün Kavramsal Katkı
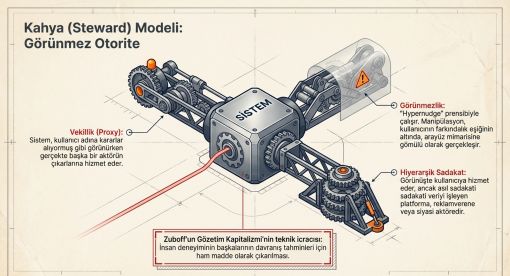
Bu çalışma, algoritmik profilleme pipeline'ının bütününü tanımlamak amacıyla Steward modeli kavramını önermektedir. Türkçe karşılığı "Kahya" olan bu kavram, büyük ev yönetiminde efendinin adına tüm işleri yürüten, kaynakları organize eden ve kararları kimin adına aldığını gözetmeksizin veren kıdemli görevliyi tanımlamaktadır.
Vekillik: Sistem, kullanıcının adına karar veriyormuş gibi görünürken aslında sistemi işleten aktörün çıkarlarına hizmet etmektedir.
Görünmezlik: Sistemin varlığı ve işleyişi kullanıcı tarafından fark edilemez.
Hiyerarşik Sadakat: Sistem, görünürde kullanıcıya hizmet ederken gerçekte veri sahibi olan platforma, reklamverene veya siyasi aktöre bağlıdır.
2.4 Davranışsal Manipülasyon ve Etik Boyut
Davranışsal manipülasyon, bu çalışmada bireyin bilişsel süreçlerini, duygusal tepkilerini veya karar alma mekanizmalarını bireyin farkında olmadığı yöntemlerle etkileyen sistematik müdahaleler bütünü olarak tanımlanmaktadır. Wachter vd. (2021), algoritmik sistemlerin yalnızca bireysel kararları değil, toplumsal eşitlik anlayışını da dönüştürdüğünü ve mevcut AB hukukunun bu dönüşüme yanıt vermekte yetersiz kaldığını göstermiştir.
Bölüm 03 · Adım 1
Veri Toplama Katmanı
3.1 Canlı Yayın ve Paket Yayın
Algoritmik profilleme pipeline'ının birinci adımı, hedef bireye ait ham verinin çeşitli kanallar aracılığıyla toplanmasıdır. Bu toplama süreci iki temel paradigma çerçevesinde gerçekleşmektedir: gerçek zamanlı davranışsal veri akışı (streaming) ve geçmişe dönük toplu veri toplama (batch processing). Hangi habere tıklandığı, sayfada ne kadar süre kalındığı, ekranın ne hızla kaydırıldığı — tüm bu etkileşimler milisaniye düzeyinde kaydedilmektedir.
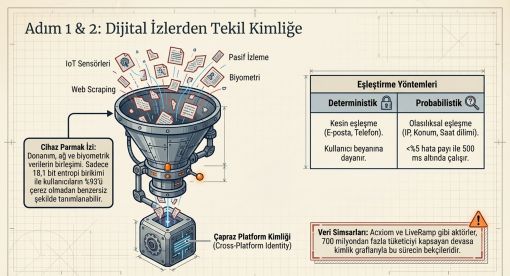
3.2 Cihaz Parmak İzi (Device Fingerprinting)
Electronic Frontier Foundation'ın Panopticlick projesi, test edilen tarayıcıların yüzde doksan dördünün yalnızca cihaz özellikleri temelinde benzersiz biçimde tanımlanabildiğini ortaya koymuştur (Guardian Digital, 2025). Cihaz parmak izi; donanım katmanı, ağ katmanı ve davranışsal katman olmak üç veri katmanının kombinasyonundan oluşmaktadır. Tuş vuruş ritmi, fare hareketi örüntüleri ve ekrana dokunma basıncı gibi biyometrik nitelikli veriler bu çerçevede toplanmaktadır.
18,1 bit entropi eşiğinin aşılmasıyla kullanıcıların yüzde doksan üçü benzersiz biçimde tanımlanabilir hale gelmektedir. Çerezlerin silinmesi, tarayıcı değiştirilmesi veya gizli mod kullanılması bu tanımlamayı engelleyememektedir (Transcend Digital, 2025).
3.3 Fiziksel İzleme ve IoT Katmanı
Veri toplama, dijital ortamın sınırlarını aşarak fiziksel dünyayı da kapsamaktadır. 2025 yılı itibarıyla dijital kimlik doğrulama işlemlerinin küresel ölçekte 86 milyar işleme ulaşması öngörülmekte ve biyometrik teknoloji pazarının 2029 yılına kadar 85 milyar dolara erişmesi beklenmektedir (State of Surveillance, 2025).
3.4 Tracking ve Scraping
Pan vd. (2025), Meta ve Google gibi platformların tracking altyapısını kullanarak dinamik ve opak algoritmalar aracılığıyla çıkarımsal profiller oluşturduğunu ve bu profillerin açık kullanıcı verilerinin çok ötesine geçtiğini ortaya koymuştur. EFF'nin 2024 tarihli FTC raporu, şirketlerin veri toplama pratiklerinin kullanıcı beklentilerini sistematik olarak aştığını teyit etmiştir.
Bölüm 04 · Adım 2
Veri Birleştirme ve Kimlik Çözümleme
4.1 Cross-Platform Identity Resolution
2025 yılı itibarıyla yapay zeka destekli kimlik grafları, profil başına 500'den fazla kimlik niteliğini birleştirme kapasitesine ulaşmış ve geleneksel kural tabanlı sistemlere kıyasla çözümleme doğruluğunu yüzde otuz dört artırmıştır. 2024 yılında saniyede 4,2 milyon kimlik olayını gerçek zamanlı olarak işleyebilen bulut tabanlı API'ler hayata geçirilmiştir (Market Reports World, 2026).
4.2 LiveRamp Davası: Ocak 2025
Cracked Labs'ın (2024) 61 sayfalık raporunda belgelenen LiveRamp, AbiliTec ve RampID sistemleri aracılığıyla küresel ölçekte 700 milyon tüketiciye ilişkin kimlik kayıtları tutmaktadır. Ocak 2025'te San Francisco Federal Mahkemesi'nde açılan toplu davada, LiveRamp'ın kullanıcıların bilgisi olmaksızın kişisel kimlik profilleri oluşturduğu ve bunları Google, Amazon, Microsoft dahil en az 62 üçüncü tarafa sattığı iddia edilmektedir (Local News Matters, 2025).
4.3 Veri Temizleme Odaları: 2024–2025 Gelişmeleri
WPP, Nisan 2025'te veri temizleme odası sağlayıcısı InfoSum'u satın alırken Publicis, Mart 2025'te yaklaşık dört milyar küresel profile erişim sağlayan Lotame'yi bünyesine katmıştır (Harro, 2026). Amazon ise Eylül 2025'te Marketing Cloud temizleme odası erişimini küçük işletmelere genişletmiştir.
4.4 California DELETE Platformu (DROP)
Ocak 2026'da hayata geçirilen DROP, California'lı tüketicilerin tek başvuruyla tüm veri simsarlarından verilerinin silinmesini talep edebildiği ilk kamu hizmeti olma özelliğini taşımaktadır. Veri simsarlarının ihlali durumundaki ceza: tüketici başına günlük 200 dolar; yüksek kayıt sayısıyla bu rakam milyonlarca dolara ulaşabilmektedir (Privacy Rights Clearinghouse, 2025).
Bölüm 05 · Adım 3
Özellik Çıkarımı ve Anlam Üretimi
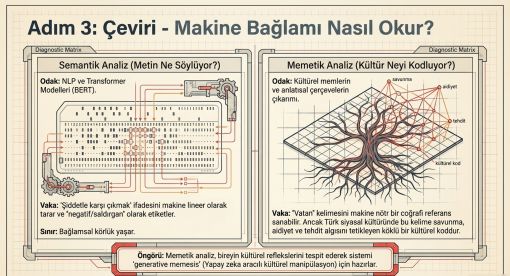
5.1 Semantik Analiz
Gnanapriya ve Anandan (2025), 10 milyonu aşkın sosyal medya gönderisini analiz ettikleri çalışmalarında BERT tabanlı duygu sınıflandırıcıların politik olaylara verilen duygusal tepkilerdeki ince ayrımları yakalamada geleneksel yöntemlere göre belirgin üstünlük sağladığını göstermiştir. Linear SVC modeli siyasi duygu sınıflandırmasında yüzde doksan bir oranında doğruluk elde etmiştir (Hossain vd., 2024).
5.2 Memetik Analiz: Özgün Katkı
Bu çalışmanın özgün katkılarından birini oluşturan memetik analiz katmanı, semantik analizin ötesine geçerek kültürel anlam birimlerinin nasıl tespit edildiğini, dolaşıma girdiğini ve manipülasyon aracına dönüştürüldüğünü incelemektedir.
Semantik analiz bir ifadenin ne anlama geldiğini saptarken, memetik analiz o ifadenin kültürel bağlamda nasıl çalıştığını ortaya koymaktadır. Örneğin "vatan" kelimesi semantik analizde nötr coğrafi referans olarak işlenebilir; oysa Türk siyasal kültüründe güçlü memetik yüke sahip karmaşık bir anlam birimi oluşturmaktadır.
2024 ABD başkanlık seçimlerine ilişkin araştırma, "generative memesis" adı verilen yeni bir paradigmayı belgelemiştir: memlerin artık bireyden bireye aktarılmak yerine yapay zeka tarafından aracılanması ve özel görseller üretilerek sistematik hedefleme (Chang vd., 2025). Romanya'nın 2024–2025 seçimlerinde adayların yapay zeka üretimi memleri milliyetçi anlatıları güçlendirmek için stratejik biçimde kullandığı belgelenmiştir (EON, 2025).
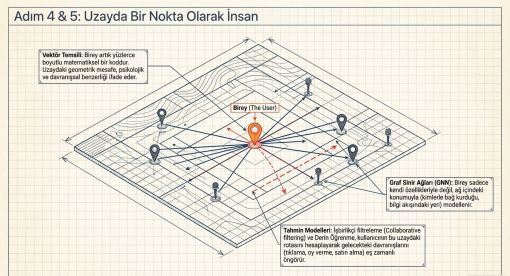
Bölüm 06 · Adım 4
Vektör Temsili ve Embedding
6.1 Yüksek Boyutlu Uzayda Bireysel Temsil
Vektör temsili, bireyi yüksek boyutlu bir uzayda tek bir noktayla tanımlayan sayısal kodlamadır. İki koordinatın bir coğrafi konumu benzersiz biçimde tarif etmesi gibi, yüzlerce boyutlu bir vektör bireyi istatistiksel olarak eşsiz kılmaktadır. ACM RecSys Challenge 2025, "Universal Behavioral Profiles" (UBP) kavramını resmi akademik literatüre kazandırmıştır: geçmiş etkileşimlerden türetilen, görev ve platform bağımsız genel amaçlı kullanıcı temsilleri (ACM, 2025).
6.2 Embedding Modellerinin Evrimi
ByteDance'in HLLM modeli hiyerarşik kullanıcı modellemesiyle oturum düzeyinde tutarlılık sağlarken; Alibaba'nın LUM modeli trilyonlarca parametre ölçeğinde güç yasası iyileştirmeleri sergilemektedir (TechRxiv, 2025). PersonaX sistemi, yalnızca davranış verilerinin yüzde otuz ile elli'sini kullanarak referans performansı yüzde on ila elli arasında iyileştirmeyi başarmıştır (ACL, 2025).
Bölüm 07 · Adım 5
Tahmin Modelleri
7.1 Graf Sinir Ağları ve Universal Behavioral Profiles
ACM RecSys Challenge 2025'te SenseLab ekibinin üçüncülük elde eden çözümü, RGCN-MTL, RGCN-TSE ve RGAT adlı üç GNN varyantını birleştirmektedir. Zaman Damgası Kodlaması içeren RGCN-TSE, mevsimsellik bilgisini gömülü temsile dahil ederek tüm görevlerde yüksek performans elde etmiştir (ACM, 2025).
7.2 KEGNN: Davranışsal-Metinsel-Ağ Entegrasyonu
KEGNN çerçevesi, RNN (zaman serisi), BiLSTM (metin) ve GCN (graf yapısı) bileşenlerini birleşik öngörücü modele entegre etmektedir. Uzun vadeli katılım tahminlerinde (üç haftaya kadar) rakip modellerden belirgin biçimde yüksek doğruluk ve F1 skorları elde edilmiştir. Ablasyon testleri, hem metin analizinin hem de ağ yapısının çıkarılmasının performansı düşürdüğünü göstermiştir (ICMR, 2025).

Bölüm 08 · Adım 6
Psikometrik Profil Çıkarımı
8.1 OCEAN Modeli
Beş Faktör Modeli (OCEAN), psikometrik profillemenin temel analitik çerçevesini oluşturmaktadır:
8.2 Schwartz Değer Teorisi
Schwartz'ın (1992) teorisi on temel değeri dört üst-düzey boyut altında organize etmektedir. Bu çerçeve OCEAN'ı tamamlamakta: OCEAN "bu kişi nasıl biri?" sorusunu yanıtlarken Schwartz "bu kişi neyi önemsiyor?" sorusunu yanıtlamaktadır. Dijital davranışsal kayıtlardan değer çıkarımı için hesaplamalı bir iskelet sunmakta; Transformer tabanlı modeller bu çıkarıma entegre edilmektedir (Emergent Mind, 2025).
8.3 Kültürel Körlük: OCEAN'ın Kalibrasyonsuzluğu
PLOS One'da Ocak 2026'da yayımlanan kapsamlı tarama, 233 yayını inceleyen ve 2004–2024 dönemini kapsayan sistematik bir değerlendirmede hiçbir psikometrik ölçeğin tam kültürlerarası skalar değişmezlik kanıtlayamadığını ortaya koymuştur (PLOS One, 2026). Bu bulgu, farklı kültürler arasında yapılan OCEAN karşılaştırmalarının sistematik ölçüm yanlılığından arındırılmış olmadığı anlamına gelmektedir.
Düşük uyumluluk skoru Batı bireyci kültürlerde bağımsız düşünce olarak yorumlanırken; kolektivisit değerlerin belirleyici olduğu Türk kültürel bağlamında aynı örüntü, grup uyumunu korumak amacıyla dışarıya yansıtılan bir yüz (face) stratejisinin ürünü olabilmektedir. Sistem bu ayrımı yapamamaktadır.
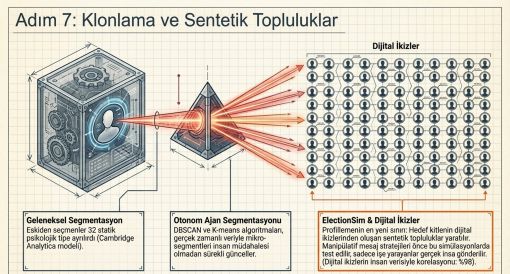
Bölüm 09 · Adım 7
Segmentasyon
9.1 Kümeleme ve Granularity-Actionability Dengesi
Simchon vd. (2024), LLM'lerin ölçeklenebilir bir "manipülasyon makinesi" oluşturma potansiyeli taşıdığını — tüketilen metin üzerinden kişilik çıkarımı yaparak bireyin benzersiz kırılganlıklarını hedefleyen, insan girdisi gerektirmeyen sistem — PNAS Nexus'ta yayımlanan çalışmalarında belgelemiştir.
9.2 Sentetik Topluluklar: 2024–2025 En Önemli Gelişme
FlockVote, 2024 ABD başkanlık seçimini test yatağı olarak kullanan LLM ajanlı seçmen simülasyon çerçevesidir (ICAIS, 2025). ElectionSim sosyal medyadan örneklenen milyonluk seçmen havuzuyla kitlesel seçmen simülasyonunu mümkün kılmaktadır (arXiv, 2024). Dijital ikiz araştırması, model çıktılarının insan verileriyle 0,98 korelasyon sergilediğini ortaya koymuştur (NN/g, 2025).
Science dergisinde Ocak 2026'da yayımlanan makale, LLM akıl yürütmesini çok-ajan mimarileriyle birleştiren sistemlerin özerk biçimde koordine olabildiğini, topluluklara sızabildiğini ve sahte uzlaşıyı verimli biçimde ürettiğini belgelemiştir (Science, 2026). Temmuz 2024'te ABD Adalet Bakanlığı, 968 X hesabını taklit eden yapay zeka güçlendirilmiş Rusya bağlantılı bot çiftliğini devre dışı bırakmıştır.

Bölüm 10 · Adım 8
Kişiselleştirilmiş İçerik Üretimi
10.1 LLM Destekli Mesaj: Maliyet ve Ölçek
Williams vd. (2025), geleneksel yöntemlerle yaklaşık 4.500 dolar maliyete ulaşacak bir seçim dezenformasyon kampanyasının, ticari bir LLM kullanılarak 1 doların altında gerçekleştirilebildiğini hesaplamıştır. Test edilen 13 LLM'nin büyük çoğunluğunun zararlı içerik taleplerine yanıt verdiği saptanmıştır (Alan Turing Enstitüsü, 2025).
10.2 Slopaganda
Klincewicz, Alfano ve Fard (2025) "slopaganda" kavramını kavramsallaştırmıştır: LLM'ler aracılığıyla kitlesel olarak üretilen, düşük kaliteli ancak yüksek hacimli yapay zeka içeriklerinin ideolojik manipülasyon amacıyla kullanılması. PNAS Nexus'taki araştırma, YZ'ye geçişin üretkenliği artırırken kaliteyi düşürmediğini DCWeekly.org vakasıyla belgelemiştir (PNAS Nexus, 2025).
10.3 Propaganda Retoriği: GPT'nin Dilsel Stratejileri
340.000 siyasi haber makalesi üzerinde yürütülen araştırma, GPT versiyonlarının propaganda tarzı içerikte tutarlı ve evrilen retorik stratejiler kullandığını ortaya koymuştur. Sınıflandırma sistemi 0,98 üzerinde AUROC değeri elde etmiştir (ScienceDirect, 2025).
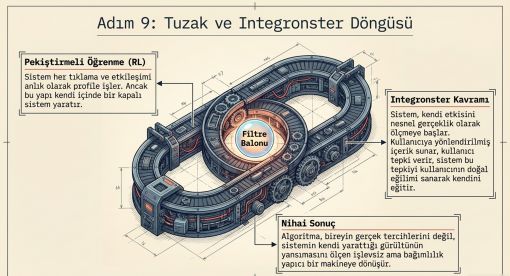
Bölüm 11 · Adım 9
Geri Besleme Döngüsü
11.1 Filtre Balonu: Deneysel Kanıt
PNAS'ta Şubat 2025'te yayımlanan çalışma, yaklaşık 9.000 katılımcıyla yürütülen dört deneyde partizan video önerilerine maruz kalmanın kısa vadede kullanıcıların tutumları üzerinde ölçülebilir kutuplaşma etkisi yaratmadığını saptamıştır (Liu vd., 2025). Ancak araştırmacılar uzun vadeli maruziyeti dışlamamaktadır.
11.2 Integronster Tehlikesi
Geri besleme döngüsünün en sinsi boyutu, sistemin kendi etkisini "doğal eğilim" olarak ölçmeye başlamasıdır. Başkaya'nın (2026) Sentetik Otoriterlik çalışmasında kavramsallaştırılan Integronster: farklı alt sistemlerin mekanik birleşiminden doğan, yazılım olarak işlev gören ancak bilimsel model olarak işe yaramaz yapılar. Sistem kendi ürettiği gürültünün yansımasını ölçmektedir.
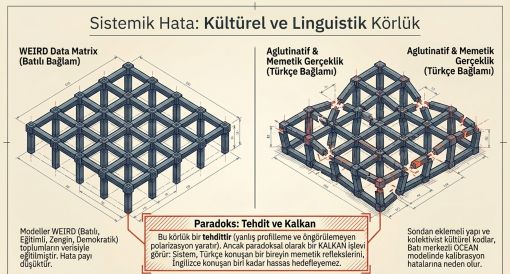
Bölüm 12
Kültürel ve Linguistik Körlük
12.1 WEIRD Örneklemi Sorunu
PNAS Nexus'ta Eylül 2024'te yayımlanan kapsamlı denetim, beş yaygın LLM'in 107 ülke genelinde kültürel yanlılığını sistematik biçimde incelemiştir. GPT-4o için kültürel yönlendirme uygulandıktan sonra bile model çıktılarıyla gerçek kültürel değerler arasındaki mesafe Uruguay ile GPT-4o arasındaki mesafeye eşdeğer kalmıştır (PNAS Nexus, 2024). FAccT 2025'te sunulan çalışma, algoritmik denetimlerin kendisinin WEIRD yanlılığı taşıdığını belgelemiştir (Urman vd., 2025).
12.2 Kültürel Körlük Paradoksu: Hem Tehdit Hem Koruma
Kültürel ve linguistik körlük, Türkiye için aynı anda hem bir tehdit hem de yapısal bir koruma kalkanı işlevi görmektedir. Tehdit boyutunda sistem hatalı profiller üretmekte ve beklenmeyen sosyal polarizasyona zemin hazırlamaktadır. Koruma boyutunda ise memetik kodların yanlış okunması ve semantik hataların birikmesi paradoks biçimde kültürel özgünlüğü koruyan bir direnç mekanizması üretmektedir.
12.3 Veri Egemenliği Savaşı
2024'te yürürlüğe giren Protecting Americans' Data from Foreign Adversaries Act, veri egemenliği rekabetinin yasal çerçeveye taşındığının ilk somut göstergesidir. Cornell araştırması, yapay zeka yazma asistanı kullanan Hindistanlı katılımcıların zamanla daha Batılılaşmış yazı tarzlarına kaydığını göstermiştir (Forward Pathway, 2025).
Bölüm 13
Güvenlik, Gizlilik ve Düzenleyici Çerçeveler
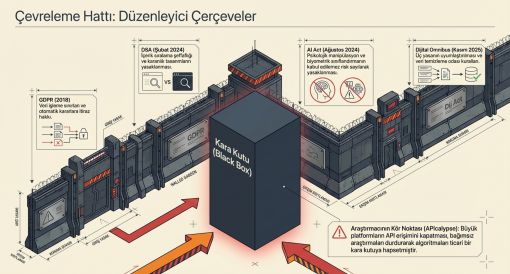
13.1 AB'nin Üçlü Yasal Yapısı
GDPR (2018'den itibaren): Kullanıcının açık rızası olmaksızın profillemeden korunma hakkı ve otomatik kararlara itiraz hakkını kapsamaktadır.
DSA (Şubat 2024'ten itibaren): Platformların içerik sıralama parametrelerini açıklamasını ve kullanıcılara veri tercihlerini kontrol etme imkânı tanımasını zorunlu kılmaktadır.
AI Act (Ağustos 2024'ten itibaren, 2027'ye kadar kademeli): Psikolojik manipülasyonu kabul edilemez risk kategorisinde değerlendirerek yasaklamaktadır (INTA, 2024).
13.2 Digital Omnibus: Kasım 2025
Avrupa Komisyonu'nun 19 Kasım 2025'te yayımladığı Dijital Omnibus, GDPR, AI Act ve Veri Yasası'nı uyumlaştırmayı ve çakışan bildirimleri tek girişe yönlendirmeyi hedeflemektedir (White & Case, 2025).
13.3 APIcalypse: Araştırmanın Kör Noktası
Cambridge Analytica skandalı sonrasında platformların API erişimini kısıtlaması "APIcalypse" olarak adlandırılan metodolojik krize yol açmıştır. X/Twitter ücretli API politikasına geçmiş; bu durum akademik araştırmayı belirli platformlara yoğunlaştırarak karanlık sosyal medya mecralarının görünmez kalmasına yol açmaktadır.
Bölüm 14
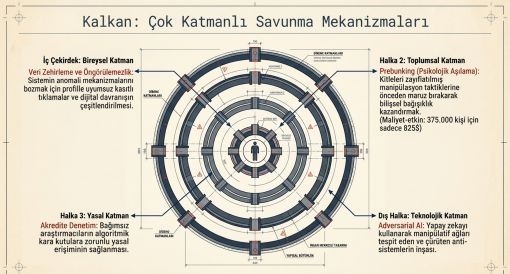
Savunma Mekanizmaları
14.1 Bireysel Katman: Veri Zehirleme
Veri zehirleme stratejisi, sistemin tahmin modelini besleyen davranışsal sinyalleri kasıtlı olarak bozmaktadır. Bireyin ilgi alanlarıyla uyuşmayan içeriklere tıklaması, profiline aykırı ürünleri araması bu stratejinin somut uygulamalarını oluşturmaktadır. Pratik etkinliği sınırlı olmakla birlikte, yeterince sürdürüldüğünde sistemin profil oluşturma kapasitesini zayıflatmaktadır.
14.2 Toplumsal Katman: Prebunking
HKS Misinformation Review'da yayımlanan çalışma, 375.597 Instagram kullanıcısını hedef alan 19 saniyelik prebunking video reklamının duygusal manipülasyona karşı doğru tanıma düzeyini istatistiksel olarak artırdığını ve yalnızca 825 dolar kampanya maliyetiyle elde edildiğini ortaya koymuştur (HKS, 2026). 33 aşılama deneyini kapsayan meta-analiz (N = 37.075), psikolojik aşılamanın güvenilir ile güvenilmez içerik arasındaki ayrımı genelleşmiş güvensizliğe yol açmadan iyileştirdiğini göstermiştir (ScienceDirect, 2025).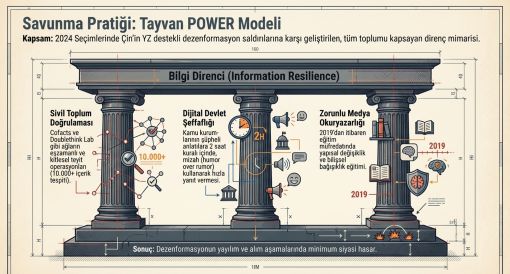
14.3 Tayvan POWER Modeli
Doublethink Lab tarafından çerçevelenen Tayvan POWER Modeli beş temel özellikten oluşmaktadır: Purpose-driven, Organic, Whole-society, Evolving, Remit-bound. 2024 seçimlerinde 10.000'i aşkın şüpheli içerik tespit edilmiş, ancak seçim sonuçları üzerindeki yabancı müdahale etkisi minimum düzeyde kalmıştır (Taiwan Insight, 2024).
Tayvan modelinin diğer ülkelere aktarımı için üç ön koşul gerekmektedir: kurumsal kapasite, siyasi irade ve güçlü sivil toplum. Bu koşulların yokluğunda yüzeysel uyarlamalar yetersiz kalmaktadır.
Bölüm 15
Tartışma
15.1 Pipeline'ın Gücü ve Yapısal Sınırları
Algoritmik profilleme pipeline'ı beş yapısal kırılganlık barındırmaktadır: veri kalitesi sorunları, kalibrasyonsuzluk, geri besleme kısır döngüsü, bireysel direnç ve "kuyruk etkileri." SCLA'nın (2025) analizinin işaret ettiği gibi, algoritmaların büyük çoğunluğu üzerindeki etkisi sınırlı olsa bile küçük bir savunmasız alt kümede dramatik sonuçlar doğurabilmektedir.
15.2 Algoritmik Determinizm mi, "Yılan Yağı" mı?
Müzakereci demokrasi üzerine yapılan araştırma bu tabloya net bir çerçeve kazandırmaktadır: algoritmalar kendi eylemlerini tek taraflı belirlemez; vatandaşların bu algoritmaların mantığını nasıl yorumladığına ilişkin veri girdilerine tepki verir ve uyum sağlar (Tandfonline, 2025). Cambridge Analytica'da bir GOP veri bilimcisinin ifadesiyle "OCEAN skoru hedeflemesinin bireysel ikna aracı olarak işlediğini kanıtlamadan şüpheci kalmaya devam edeceğim." Sistemin asıl tehlikesi, bireyi yönetmesinden değil; yarattığı bilgi asimetrisinden kaynaklanmaktadır.
15.3 Algoritmik Bellek ve Demokratik Ortak Hafıza
Toda Barış Enstitüsü'nün İspanya örneği üzerinden gösterdiği "algoritmik bellek" dinamiği, platformların tarih anlatılarını algoritmik olarak yeniden çerçeveleyebildiğini ortaya koymaktadır. Türkiye bağlamında bu dinamik özellikle kritiktir: toplumsal hafızanın yeniden çerçevelenmesi, mevcut siyasi güç ilişkilerini pekiştirecek içeriklerin algoritmik olarak öne çıkarılmasıyla gerçekleşebilmektedir (Toda, 2025).
15.4 Yeni Bir Dijital Toplumsal Sözleşme
Edelman Trust Barometresi'nin (2025) küresel ölçekte hükümet kurumlarına duyulan güvenin yüzde kırk bire gerilediğini belgelemesi, teknik çözümlerin ötesinde normatif bir yeniden inşayı zorunlu kılmaktadır. Yeni dijital toplumsal sözleşme üç ilkeyi eş zamanlı hayata geçirmek zorundadır: algoritmik şeffaflık, anlamlı rıza ve hesap verebilirlik.
Sonuç
Bu çalışma, algoritmik profilleme pipeline'ının veri toplamadan davranışsal manipülasyona uzanan dokuz aşamalı anatomisini sistematik biçimde haritalandırmıştır. Türkçe akademik literatürde bu kapsamda ilk kez gerçekleştirilen bu bütünleşik teknik inceleme, pipeline'ın yalnızca mühendislik boyutunu değil; psikolojik, kültürel, jeopolitik ve etik boyutlarını da ele almıştır.
Profilleme sisteminin sizi tahmin edemediği her an — özerkliğinizi koruduğunuz andır. Kahya'nın gücü görünmezliğinden beslenmektedir. Görünür kılmak, ilk ve en kritik savunma adımıdır.
Yaşar Başkaya, Nisan 2026